What is shannon fano encoding and how is it used in data compression.
Author
Vannsh Jani
Published
August 30, 2023
Shannon Fano encoding
The Shannon fano algorithm is a lossless data compression technique. Data compression is the process of encoding or converting data in such a way that it consumes less memory space. Hence, it reduces the resources required to store and transmit data.
For eg, it would make more sense to assign symbols or characters occuring more frequently to consume less number of bits than to assign equal bits to all characters. Hence, it assigns codes of variable lengths to each character. In the realm of data compression, two distinct but connected methods for creating a prefix code for the characters is Shannon Fano encoding.
Algorithm
We find out the frequency or probability of occurance of each character or symbol and store it in an array.
We sort the array in decreasing order based on probability(frequency).
Then, we split the list in two parts with as much similarity(least variance) between the frequency/probability of left and right parts.
We assign the binary digit ‘0’ to the left part and binary digit ‘1’ to the right part. This implies that symbols in the left section will begin with ‘0’ and symbols in the right section will begin with ‘1’.
We repeat steps 3 and 4 by splitting each section into left and right sections and assigning the binary digits ‘0’ and ‘1’ to them unitl each section is left with just one symbol(analogous to leaf node of binary tree).
Let’s better understand shannon-fano and visualize it using examples. We’ll encode the characters of the following sentence.
“aaaaaaaabbbbccd”
Let’s first calculate the probability of each character in the above statement, and sort them based on probabilities in descending order.
sentence ="aaaaaaaabbbbccd"def generate_prob(sentence): d={} special=0for c in sentence:if c==","or c=="."or c==" ": special+=1continueelif c.lower() in d: d[c.lower()] +=1else: d[c.lower()] =1 total_char =len(sentence)-specialfor key in d: d[key] = d[key]/total_charreturn dseq = generate_prob(sentence)seq=sorted(seq.items(),key=lambda item: item[1], reverse=True)d =dict(seq)d
We create nodes for the sequence and build a tree following the top to bottom approach.
Since we want the splits to have similar total probabilities, we can assign ‘0’ and ‘1’ alternatively on the descended probability sequence or we can create the left subset until the probabilities of all the subsets approximately reach half of the total probability value.
class Node:def__init__(self,char,prob):self.char=charself.p=probself.code=""self.left=Noneself.right=Noneinitial=""for c in seq: initial+=c[0]root = Node(initial,1)def split(node): left_subset={} right_subset={} total_p = node.p half_p = total_p/2sum=0 index =0 seq=node.charfor c in seq:ifsum>=half_p:breaksum+=d[c] index+=1 left_char = seq[:index] right_char = seq[index:]for l in left_char: left_subset[l]=d[l]for r in right_char: right_subset[r]=d[r]return left_subset,right_subsetdef Build_tree(root):iflen(root.char)==1:return left_subset,right_subset = split(root) left_char="" right_char=""for c in left_subset: left_char+=cfor cr in right_subset: right_char+=cr left_prob =sum(left_subset.values()) right_prob =sum(right_subset.values()) left_node = Node(char=left_char,prob=left_prob) right_node = Node(char=right_char,prob=right_prob) root.left = left_node root.right = right_node Build_tree(left_node) Build_tree(right_node)Build_tree(root)def assign_codes(root):if root.left isNoneand root.right isNone:returnif root.left isnotNone: root.left.code ="0"+ root.codeif root.right isnotNone: root.right.code ="1"+ root.code assign_codes(root.left) assign_codes(root.right)assign_codes(root)total_bits=0def print_codes(root):global total_bitsif root isnotNone:if (len(root.char)==1): total_bits +=len(root.code)*sentence.count(root.char)print(f"Character is '{root.char}', probability is {round(root.p,4)} and code is {root.code}") print_codes(root.left) print_codes(root.right)print_codes(root)
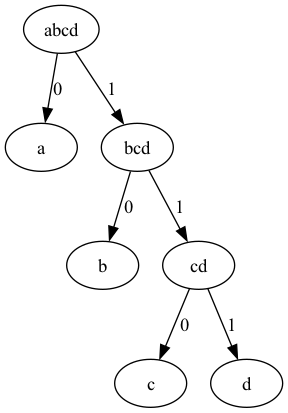
Character is 'a', probability is 0.5333 and code is 0
Character is 'b', probability is 0.2667 and code is 01
Character is 'c', probability is 0.1333 and code is 011
Character is 'd', probability is 0.0667 and code is 111
Hence, we follow the top-bottom approach, where we add ‘0’ to the left subset and ‘1’ to the right subset as we traverse down the tree.
Visualizing the Binary Tree
Results and Observations
If we consider the “ascii” encoding, we would have to consider 8 bits for each letter, whereas we consume less number of bits using shannon-fano encoding.
print(f"No.of bits using ascii = {len(sentence)*8}")print(f"No.of bits using shannon-fano = {total_bits}")
No.of bits using ascii = 120
No.of bits using shannon-fano = 25
Shannon-fano algorithm certainly performs better than the ascii encoding and does a decent job.
Compression ratio
The compression ratio tells us how much smaller the compressed data is compared to the original data. The higher the compression ratio, the better the compression.
Compression ratio = Before Compression / After compression
b =len(sentence)*8a = total_bitsprint(f"compression ratio is,",(b/a))
compression ratio is, 4.8
Entropy
Entropy is the measure of randomness of data, higher the entropy more random the data. More random the data, the more number of bits we need to measure it.
\[
H(x) = -\Sigma_{i=1}^n p(x_i)log_2(p(x_i))
\]
import numpy as npdef calc_entropy(p):return-1* p * np.log2(p)entropy =0for c in d: entropy += calc_entropy(d[c])print(f"Entropy of input data is {entropy}")
Entropy of input data is 1.640223928941852
It turns out, shannon fano algorithm is not the most optimized algorithm and may not work always. The Huffman encoding which is a slightly modified version of the shannon-fano optimizes the data compression even further.